Standard Deviation of a Data Set
Definition of the Standard Deviation
The standard deviation is a measure of how close the data values in a data set are from the mean. It is a quantity that is small when data is distributed close to the mean and large when data is far form the mean.
let x1, x2, x3 ... xN be a set of data with a mean μ. To measure how far is a data value xi from the mean, we may use the difference di given by
di = xi - μ
The problem with the above definition is that di may be negative or positive and when you add all the di for all data values to obtain an average, they may cancel each other. Hence we square di, average them and then take the square root.
The standard deviation σ of a population having N elements is defined by
\[ \sigma =\sqrt {\dfrac{\sum_{i=1}^{N} (x_i - \mu)^2}{N}} \]
where \( \mu \) is the mean given by
\[\mu = \dfrac{\sum_{i=1}^{N} x_i}{N}\]
In a statistical study, we may have large populations and therefore computing the standard deviation for the whole population may be costly and time consuming hence the idea of using samples from the population to estimate the standard deviation.
The standard deviation s of a data set of a sample having N elements is defined by
\[s =\sqrt {\dfrac{\sum_{i=1}^{N} (x_i - \overline{x})^2}{N - 1}}\]
where
\[\overline{x} = \dfrac{\sum_{i=1}^{N} x_i}{N}\]
The main difference between the two formulas is the division by N and N - 1. We use N - 1 in the formula of the standard deviation for samples to compensate for the fact that the number of data values in a population is much larger than the number of data values in a sample. Note also that for N very large, the two formulas would give very close values.
An online calculator to compute the standard deviation is included.
Examples on Standard Deviation
Example 1
Three data sets representing three populations are given below.
A:{1,1,15,15} B:{1,7,9,15} C:{7,7,9,9}
Calculate the mean and the standard deviation for each data set. Compare the means and the standard deviation of the three sets.
Solution to Example 1
For set A
\[\mu_A = \dfrac{1 + 1 + 15 + 15 + 11}{4} = 8\]
\[\sigma_A=\sqrt {\dfrac{(1 - 8)^2 + (1 - 8)^2 + (15 - 8)^2 + (15 - 8)^2}{4}} = 7\]
For set B
\[\mu_B = \dfrac{1 + 7 + 9 + 15}{5} = 8\]
\[\sigma_B =\sqrt {\dfrac{(1 - 8)^2 + (7 - 8)^2 + (9 - 8)^2 + (15 - 8)^2}{4}} = 5\]
For set C
\[\mu_C = \dfrac{7 + 7 + 9 + 9}{4} = 8\]
\[\sigma_C =\sqrt {\dfrac{(7 - 8)^2 + (7 - 8)^2 + (9 - 8)^2 + (9 - 8)^2}{4}} = 1\]
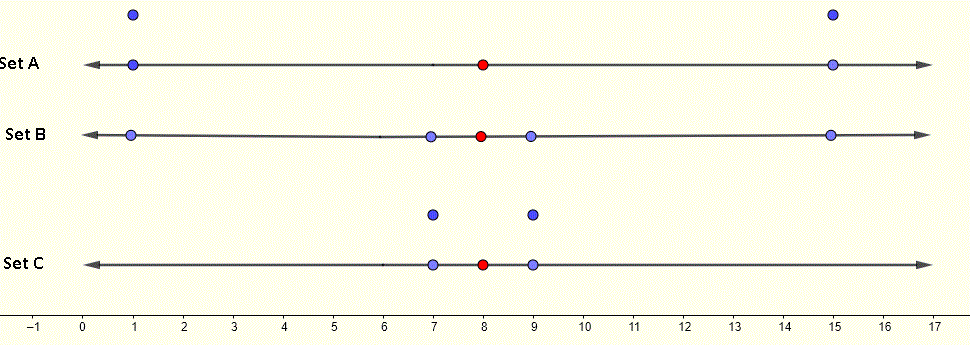
The means of the three sets are equal to 8 (red dot in graph) and the standard deviations are different. We can see on the graphs on the number lines below of the three sets. It is graphically clear that the data values in Set C are close to the mean and that is why this set has the smallest standard deviation. The graphs on the number line of set A and B shows that data in Set A is more dispersed than the data in set B, hence the standard deviation is set A is larger than of set B.
Example 2
Two data sets representing two populations are given below.
A:{2 , 3 , 5 , 8 , 10} B:{3 , 4 , 6 , 9 , 11}
Calculate the mean and the standard deviation for each data set. Compare the means and the standard deviation of the two sets.
Solution to Example 2
For set A
\[\mu_A = \dfrac{2 + 3 + 5 + 8 + 10}{5} = 5.6\]
\[\sigma_A=\sqrt {\dfrac{(2 - 5.6)^2 + (3 - 5.6)^2 + (5 - 5.6)^2 + (8 - 5.6)^2 + (10 - 5.6)^2}{5}}\]
\[=3.0\]
For set B
\[\mu_B = \dfrac{3 + 4 + 6 + 9 + 11}{5} = 6.6\]
\[\sigma_B =\sqrt {\dfrac{(2 - 5.6)^2 + (3 - 5.6)^2 + (5 - 5.6)^2 + (8 - 5.6)^2 + (10 - 5.6)^2}{5}} \]
=3.0
The means are different and the standard deviation are equal. This means the data values in the two sets are distributed in the same way around the mean. The two sets A and B are shown below on number lines. Although the two sets are different, the distances between the data values and the mean are correspondingly equal and that explains why the two sets have equal standard deviations.

Example 3
The scores in a Physics exam of students in two classes A and B have the following means and standard deviations.
Class A: mean = 78 and standard deviation = 5
Class A: mean = 78 and standard deviation = 15
What can we conclude about the performance of students in the two classes?
Solution to Example 3
The scores of the two classes have equal means but the standard deviation of class B is higher than the standard deviation of class A. This means that the scores in class B are more dispersed and therefore in class B and therefore some students might have scored much lower then the mean while other students might have scored much higher than the mean. In general students in class A scored closer to the mean.
Example 4
The mean of a set of data values is equal to μ and its standard deviation is equal to σ. If all the data values in the set are increased by the same value k, what is the mean and the standard deviation after the increase?
Solution to Example 4
If you plot all data values on a number line and add k to these values and graph them again on the same number line, all points on the number line would be shifted by the same distance k and therefore the mean also increases by k. However the standard deviation will not change because it is a measure of the distance between the data values and the mean and they all shifted by the same value k.
The mean and standard deviation of the set { x_1, x_2 ,... x_N } are given by
\[\mu = \dfrac{\sum_{i=1}^{N} x_i}{N}\]
and
\[\sigma =\sqrt {\dfrac{\sum_{i=1}^{N} (x_i - \mu)^2}{N}}\]
We now add k to each data value x_i and compute the mean and standard deviation
\[\mu_k = \dfrac{\sum_{i=1}^{N} (x_i + k)}{N} = \dfrac{\sum_{i=1}^{N} x_i}{N} + \dfrac{\sum_{i=1}^{N} k}{N} = \mu + k\]
\[\sigma_k =\sqrt {\dfrac{\sum_{i=1}^{N} ((x_i + k) - \mu_A)^2}{N}} = \sqrt {\dfrac{\sum_{i=1}^{N} (x_i + k - (\mu + k))^2}{N}}\]
Simplify the numerator to obtain
\[\sigma_k = \sqrt {\dfrac{\sum_{i=1}^{N} (x_i - \mu )^2}{N}}\]
Hence if we increase all data values in a set by the same amount k, the mean increases by k but the standard deviation does not change.
More References and Links
Standard deviation.
Mean, Median and Mode
Mean and Standard deviation.