Desviación Estándar de un Conjunto de Datos
Definición de la Desviación Estándar
La desviación estándar es una medida de qué tan cerca están los valores de datos de un conjunto respecto a la media. Es una cantidad pequeña cuando los datos están distribuidos cerca de la media y grande cuando están lejos de la media.
Sea x1, x2, x3 ... xN un conjunto de datos con una media μ. Para medir qué tan lejos está un valor de dato xi de la media, podemos usar la diferencia di dada por:
di = xi - μ
El problema con la definición anterior es que di puede ser negativa o positiva, y al sumar todos los di para todos los valores de datos para obtener un promedio, podrían cancelarse entre sí. Por lo tanto, elevamos al cuadrado di, los promediamos y luego tomamos la raíz cuadrada.
La desviación estándar σ de una población con N elementos se define por:
\[ \sigma =\sqrt {\dfrac{\sum_{i=1}^{N} (x_i - \mu)^2}{N}} \]
donde \( \mu \) es la media dada por:
\[\mu = \dfrac{\sum_{i=1}^{N} x_i}{N}\]
En un estudio estadístico, podemos tener poblaciones grandes y, por lo tanto, calcular la desviación estándar para toda la población puede ser costoso y llevar mucho tiempo. De ahí la idea de usar muestras de la población para estimar la desviación estándar.
La desviación estándar s de un conjunto de datos de una muestra con N elementos se define por:
\[s =\sqrt {\dfrac{\sum_{i=1}^{N} (x_i - \overline{x})^2}{N - 1}}\]
donde
\[\overline{x} = \dfrac{\sum_{i=1}^{N} x_i}{N}\]
La principal diferencia entre las dos fórmulas es la división por N y N - 1. Usamos N - 1 en la fórmula de la desviación estándar para muestras para compensar el hecho de que el número de valores de datos en una población es mucho mayor que el número de valores de datos en una muestra. Note también que para N muy grande, las dos fórmulas darían valores muy cercanos.
Se incluye una calculadora en línea para calcular la desviación estándar.
Ejemplos de Desviación Estándar
Ejemplo 1
Se dan a continuación tres conjuntos de datos que representan tres poblaciones.
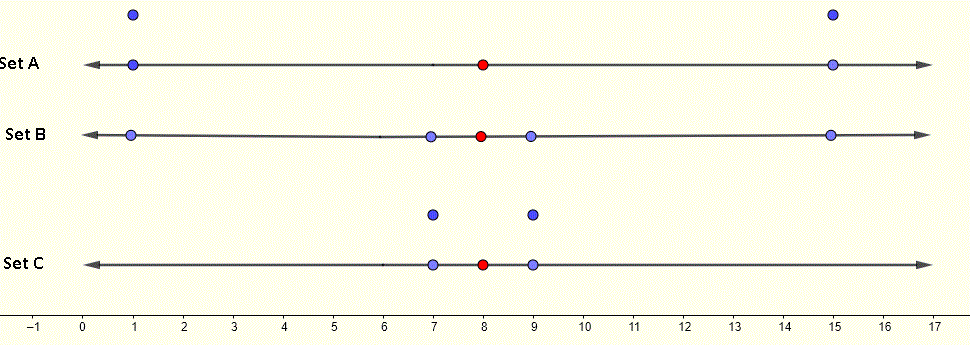
A:{1,1,15,15} B:{1,7,9,15} C:{7,7,9,9}
Calcule la media y la desviación estándar para cada conjunto de datos. Compare las medias y la desviación estándar de los tres conjuntos.
Solución del Ejemplo 1
Para el conjunto A
\[\mu_A = \dfrac{1 + 1 + 15 + 15}{4} = 8\]
\[\sigma_A=\sqrt {\dfrac{(1 - 8)^2 + (1 - 8)^2 + (15 - 8)^2 + (15 - 8)^2}{4}} = 7\]
Para el conjunto B
\[\mu_B = \dfrac{1 + 7 + 9 + 15}{4} = 8\]
\[\sigma_B =\sqrt {\dfrac{(1 - 8)^2 + (7 - 8)^2 + (9 - 8)^2 + (15 - 8)^2}{4}} = 5\]
Para el conjunto C
\[\mu_C = \dfrac{7 + 7 + 9 + 9}{4} = 8\]
\[\sigma_C =\sqrt {\dfrac{(7 - 8)^2 + (7 - 8)^2 + (9 - 8)^2 + (9 - 8)^2}{4}} = 1\]
Las medias de los tres conjuntos son iguales a 8 (punto rojo en la gráfica) y las desviaciones estándar son diferentes. Podemos ver en los gráficos en las líneas numéricas siguientes de los tres conjuntos. Gráficamente es claro que los valores de datos en el Conjunto C están cerca de la media y es por eso que este conjunto tiene la desviación estándar más pequeña. Los gráficos en la línea numérica del conjunto A y B muestran que los datos en el Conjunto A están más dispersos que los datos en el conjunto B, de ahí que la desviación estándar del conjunto A sea mayor que la del conjunto B.
Ejemplo 2
Se dan a continuación dos conjuntos de datos que representan dos poblaciones.
A:{2 , 3 , 5 , 8 , 10} B:{3 , 4 , 6 , 9 , 11}
Calcule la media y la desviación estándar para cada conjunto de datos. Compare las medias y la desviación estándar de los dos conjuntos.
Solución del Ejemplo 2
Para el conjunto A
\[\mu_A = \dfrac{2 + 3 + 5 + 8 + 10}{5} = 5.6\]
\[\sigma_A=\sqrt {\dfrac{(2 - 5.6)^2 + (3 - 5.6)^2 + (5 - 5.6)^2 + (8 - 5.6)^2 + (10 - 5.6)^2}{5}}\]
\[=3.0\]
Para el conjunto B
\[\mu_B = \dfrac{3 + 4 + 6 + 9 + 11}{5} = 6.6\]
\[\sigma_B =\sqrt {\dfrac{(3 - 6.6)^2 + (4 - 6.6)^2 + (6 - 6.6)^2 + (9 - 6.6)^2 + (11 - 6.6)^2}{5}} \]
=3.0
Las medias son diferentes y las desviaciones estándar son iguales. Esto significa que los valores de datos en los dos conjuntos se distribuyen de la misma manera alrededor de la media. Los dos conjuntos A y B se muestran a continuación en líneas numéricas. Aunque los dos conjuntos son diferentes, las distancias entre los valores de datos y la media son correspondientemente iguales y eso explica por qué los dos conjuntos tienen desviaciones estándar iguales.

Ejemplo 3
Las calificaciones en un examen de Física de estudiantes en dos clases A y B tienen las siguientes medias y desviaciones estándar.
Clase A: media = 78 y desviación estándar = 5
Clase B: media = 78 y desviación estándar = 15
¿Qué podemos concluir sobre el rendimiento de los estudiantes en las dos clases?
Solución del Ejemplo 3
Las calificaciones de las dos clases tienen medias iguales, pero la desviación estándar de la clase B es mayor que la desviación estándar de la clase A. Esto significa que las calificaciones en la clase B están más dispersas y, por lo tanto, algunos estudiantes podrían haber obtenido puntuaciones mucho más bajas que la media, mientras que otros estudiantes podrían haber obtenido puntuaciones mucho más altas que la media. En general, los estudiantes de la clase A obtuvieron calificaciones más cercanas a la media.
Ejemplo 4
La media de un conjunto de valores de datos es igual a μ y su desviación estándar es igual a σ. Si todos los valores de datos en el conjunto se incrementan en el mismo valor k, ¿cuál es la media y la desviación estándar después del incremento?
Solución del Ejemplo 4
Si grafica todos los valores de datos en una línea numérica y suma k a estos valores y los vuelve a graficar en la misma línea numérica, todos los puntos en la línea numérica se desplazarían la misma distancia k y, por lo tanto, la media también aumenta en k. Sin embargo, la desviación estándar no cambiará porque es una medida de la distancia entre los valores de datos y la media, y todos se desplazaron el mismo valor k.
La media y la desviación estándar del conjunto { x_1, x_2 ,... x_N } están dadas por
\[\mu = \dfrac{\sum_{i=1}^{N} x_i}{N}\]
y
\[\sigma =\sqrt {\dfrac{\sum_{i=1}^{N} (x_i - \mu)^2}{N}}\]
Ahora sumamos k a cada valor de dato x_i y calculamos la media y la desviación estándar
\[\mu_k = \dfrac{\sum_{i=1}^{N} (x_i + k)}{N} = \dfrac{\sum_{i=1}^{N} x_i}{N} + \dfrac{\sum_{i=1}^{N} k}{N} = \mu + k\]
\[\sigma_k =\sqrt {\dfrac{\sum_{i=1}^{N} ((x_i + k) - \mu_k)^2}{N}} = \sqrt {\dfrac{\sum_{i=1}^{N} (x_i + k - (\mu + k))^2}{N}}\]
Simplificando el numerador obtenemos
\[\sigma_k = \sqrt {\dfrac{\sum_{i=1}^{N} (x_i - \mu )^2}{N}}\]
Por lo tanto, si aumentamos todos los valores de datos en un conjunto en la misma cantidad k, la media aumenta en k pero la desviación estándar no cambia.
Más Referencias y Enlaces
Desviación estándar (Wikipedia).
Media, Mediana y Moda
Problemas de Media y Desviación Estándar.